Attention is All You Need
In the realm of artificial intelligence and machine learning, breakthroughs often come in waves, driven by innovative concepts that redefine how systems perceive, process, and generate information. Among these waves, one particularly significant innovation emerged with the introduction of the Transformer architecture, where the groundbreaking paper titled “Attention is All You Need” by Vaswani et al. in 2017 ignited a paradigm shift in natural language processing (NLP) and beyond. This article explores the transformative power of attention mechanisms and how they have revolutionized the field of machine learning.
Unveiling the Transformer Architecture
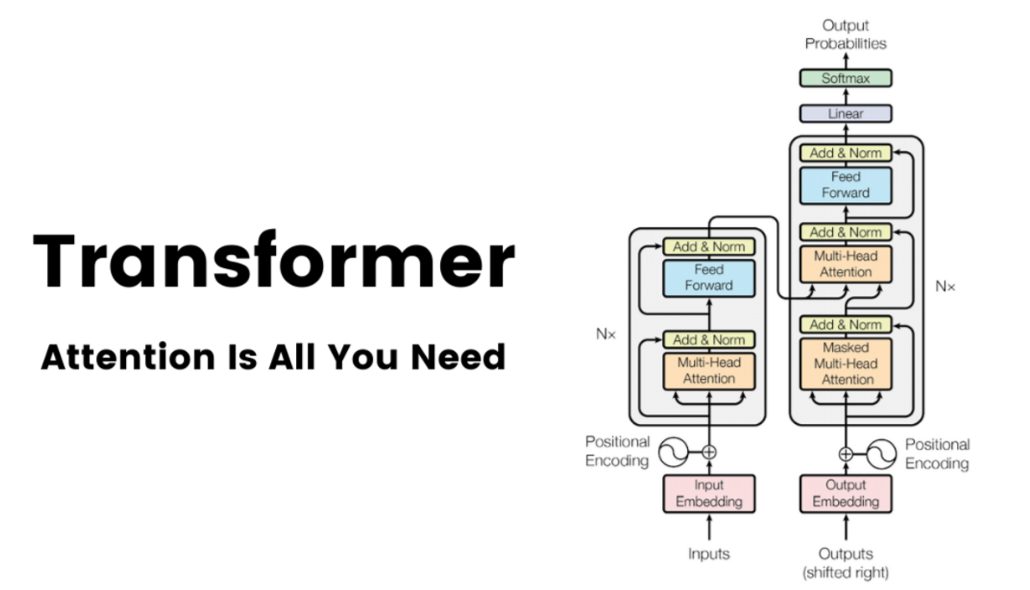
Before delving into the revolutionary impact of attention mechanisms, it’s crucial to understand the Transformer architecture’s fundamental principles. Unlike traditional sequence-to-sequence models, such as recurrent neural networks (RNNs) and long short-term memory networks (LSTMs), Transformers rely solely on self-attention mechanisms, eliminating the need for sequential processing.
At the heart of the Transformer lies the attention mechanism, a concept inspired by human cognition that enables the model to focus on relevant parts of the input sequence when making predictions. This attention mechanism allows each word or token in the input sequence to attend to every other word, capturing dependencies and relationships more effectively.
Attention Mechanism: The Driving Force
The key innovation introduced by “Attention is All You Need” is the self-attention mechanism, which enables Transformers to weigh the importance of different parts of the input sequence dynamically. Unlike traditional approaches that process sequences sequentially, self-attention allows Transformers to process all input tokens simultaneously, enabling parallelization and significantly speeding up training.
This attention mechanism operates through a series of attention heads, each responsible for capturing different aspects of the input sequence. By attending to relevant information across the entire sequence, Transformers can learn complex patterns and relationships, making them highly effective in tasks such as machine translation, text summarization, and sentiment analysis.
Empowering Language Understanding
One of the most compelling applications of Transformers is in the field of natural language understanding (NLU). By leveraging attention mechanisms, Transformers excel at capturing contextual information and long-range dependencies in text, enabling more accurate and nuanced language understanding.
In tasks like language modeling and named entity recognition, Transformers outperform traditional models by a significant margin, showcasing their ability to understand and generate human-like text. Moreover, pre-trained Transformer models, such as BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), have become foundational in many NLP applications, setting new benchmarks in performance and versatility.
Beyond Natural Language Processing
While Transformers initially gained prominence in NLP, their impact extends far beyond language-related tasks. In computer vision, for instance, vision Transformers (ViTs) have demonstrated remarkable performance in image classification and object detection tasks, challenging the dominance of convolutional neural networks (CNNs).
By treating images as sequences of patches and applying self-attention mechanisms, ViTs can effectively capture spatial relationships and global context, leading to more robust and interpretable representations. This convergence of vision and language processing exemplifies the versatility and adaptability of Transformer architectures across diverse domains.
Challenges and Future Directions
Despite their transformative impact, Transformers still face challenges, particularly in terms of scalability and efficiency. The computational complexity of self-attention mechanisms poses limitations on the size of input sequences and the training process’s speed, hindering their application to larger datasets and real-time systems.
Efforts to address these challenges are underway, with research focusing on optimizing Transformer architectures, developing more efficient attention mechanisms, and exploring novel training techniques. Moreover, the ongoing evolution of hardware accelerators, such as graphical processing units (GPUs) and tensor processing units (TPUs), promises to enhance the scalability and performance of Transformers further.
Looking ahead, the future of machine learning undoubtedly lies in the continued exploration and refinement of attention mechanisms and Transformer architectures. From advancing NLP to revolutionizing computer vision and beyond, attention truly is all we need to unlock the full potential of artificial intelligence.
Conclusion
The introduction of attention mechanisms and Transformer architectures has ushered in a new era of machine learning, redefining how systems perceive, process, and generate information. By enabling models to dynamically focus on relevant parts of input sequences, attention mechanisms have revolutionized natural language processing, computer vision, and beyond.
As researchers continue to push the boundaries of what is possible with Transformers, the impact of attention-based models is poised to grow exponentially, driving innovation across a wide range of applications and industries. In a world increasingly shaped by artificial intelligence, attention truly is all we need to pave the way for a future where machines understand and interact with the world in increasingly human-like ways.





